You don't need a vector store
In Edgar.tools we built Disclosure Search for SEC filings without a vector store. No embeddings, no RAG pipeline, no inference cost per query. Then a user proved why it worked.

The user was digging into Amazon's 10-Q – the Other Income/Expense table. Line items: marketable equity securities valuation, equity warrant gains, reclassification adjustments. The numbers didn't explain themselves. The paragraph below the table did:
She asked two questions: can you get at this text programmatically? And what about when you don't know what to search for? Her instinct was embeddings. She didn't need them. Neither did we.
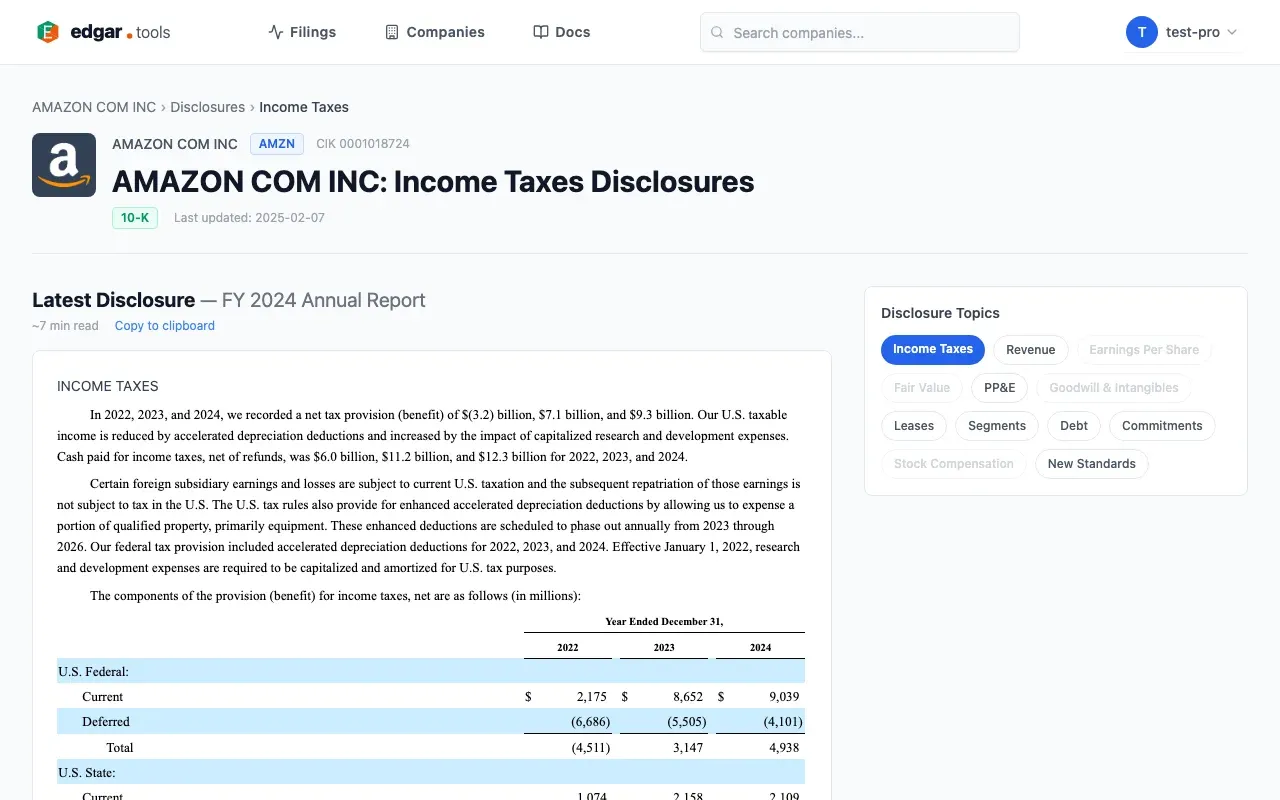
The text below the table
Our user found the Anthropic paragraph because she knew to look. Most of the time, you don't.
A 10-K runs 200+ pages. Revenue recognition policies, litigation disclosures, risk factors, commitments - every category has narrative text that explains the numbers. The paragraph that names Anthropic sits in the same filing as hundreds of other paragraphs, most of them unchanged boilerplate from the prior year.
The tools are blunt: read the whole filing, or ctrl+F and hope you guessed the right keyword.
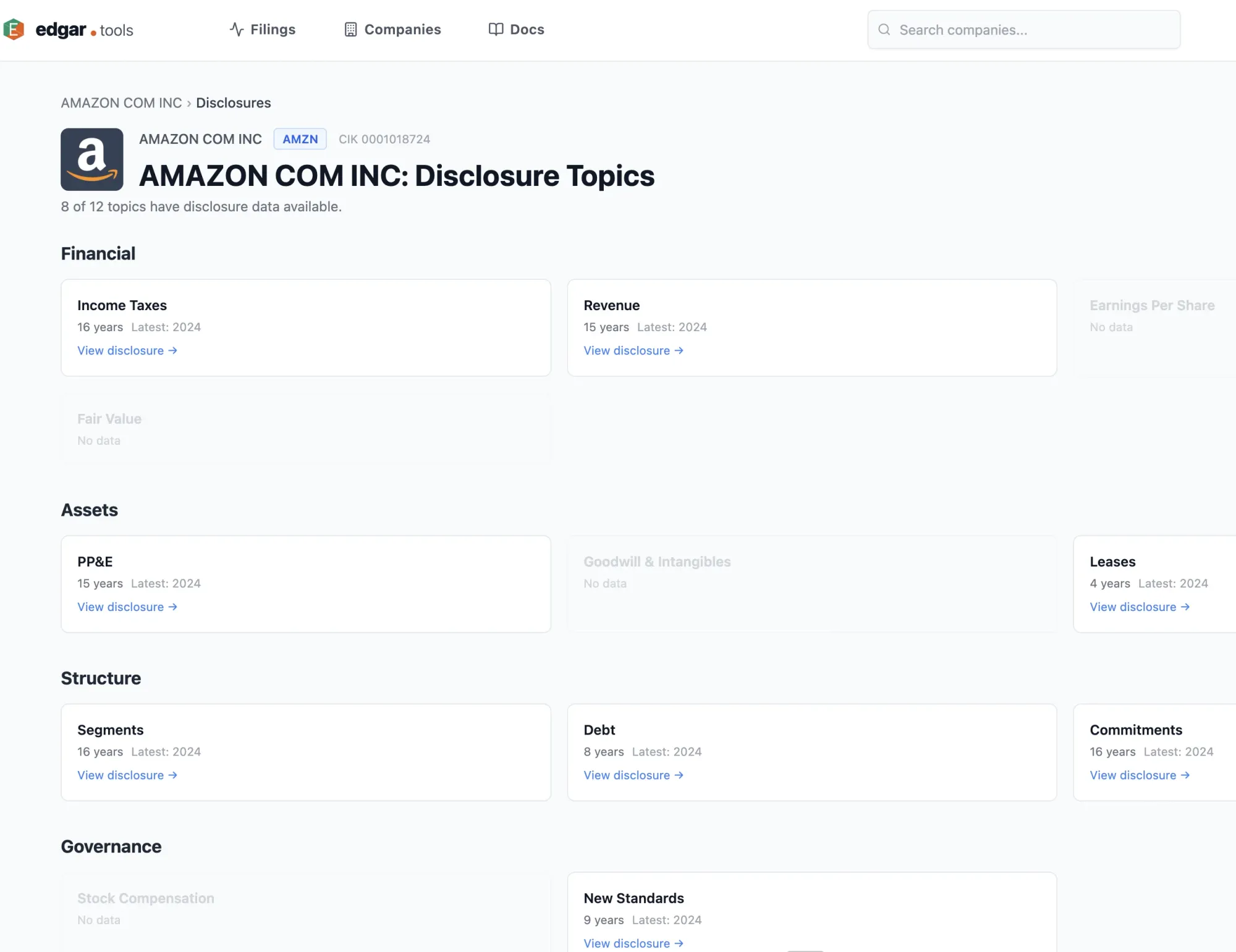
How far can you push keyword search?
Further than you'd expect – if the documents have structure.
SEC filings have something most document corpora don't: XBRL. Every major SEC filing already has its disclosures machine-tagged and categorized. We search those labels, not the raw text. The taxonomy covers roughly 18,000 elements. Revenue recognition has a tag. Lease obligations have a tag. Litigation disclosures have a tag. This means you can search actual disclosure sections, scoped by topic, instead of raw HTML or full filing text. Where generic RAG systems chunk filings into flat text and search for similarity across the chunks, XBRL-aware search treats filings as structured documents with labeled sections – the difference between searching a book and searching its index.
That handles topic-level discovery – our user could browse Fair Value disclosures without a keyword. But her second question was about terminology: "convertible" might be "convertible notes" or "convertible debt" in the filing. We added five techniques to close that gap.
Query expansion. When a user searches "convertible" the search also matches "convertible notes" and "convertible debt". A search for "fair value" also matches "ASC 820" and the Level 1/2/3 measurement hierarchy. The system maintains 47 financial synonym groups and 28 accounting standard cross-references, so searches work even when the filing uses different terminology than the query.
Proximity matching. Multi-word queries require terms to appear near each other – within the same passage, not just somewhere in a 200-page document. "Executive compensation" returns passages that discuss executive compensation, not filings where "executive" appears in one section and "compensation" in another.
Novelty scoring. Every result is compared against the same disclosure from the prior filing. Paragraphs unchanged from last year score low. Paragraphs with new language or changed wording score high. Boilerplate recedes; actual changes surface. This is precisely what an analyst tracking a company across quarters needs.
Changed-text filtering. Beyond ranking by how much changed, there's a stronger mode: filter results to only those where your search terms appear specifically in the paragraphs that changed. "Find litigation disclosures that actually changed" rather than "find filings that mention litigation somewhere in boilerplate that's been there for five years."
Smart acronym matching. Short uppercase terms – AI, ESG, ROE – are matched case-sensitively to prevent false positives. Searching "AI" doesn't match every instance of "it" or "us" scattered through a 200-page document. This is domain-specific behavior that generic search engines don't have.
These techniques close most of the gap between naive keyword search and full semantic search.
The LLM is a compiler
We didn't hire an information retrieval researcher. We didn't hand-curate synonym tables. We used Claude (Opus) to generate them.
Not at query time. Not as a runtime service. At build time: we gave the model context about SEC filings, XBRL taxonomy structure, and financial disclosure language, then had it generate the complete synonym maps, expansion rules, and topic clusters as code.
Consider what vector embeddings actually encode. They capture relationships between concepts - what a neural network learned about which terms are semantically related. "Revenue recognition" and "revenue from contracts with customers" land near each other in embedding space because the model learned they're connected.
That relational knowledge isn't locked inside the model's weights. You can ask the model to externalize it. Instead of deploying a model to compute similarity scores at query time, we had the model express its understanding of SEC filing language as explicit, readable rules. "Revenue recognition" maps to "revenue from contracts with customers" and the relevant ASC 606 references. "Antitrust" maps to "competition law," "monopoly," and "anticompetitive." These are the same conceptual relationships that an embedding model would capture, written out as a lookup table you can read and debug.
We used the LLM as a compiler, not an oracle. The model didn't invent anything – every technique exists in IR textbooks. Its job was to translate domain knowledge into deterministic logic that runs without the model. After which, the model's job was done.
What you gain, what you trade
Run the same search tomorrow, you get the same results. Run it on a different machine, same results. That matters in financial analysis, where reproducibility isn't optional. The logic is inspectable: you can read every synonym mapping and expansion rule. You can test them. You can file a bug when one is wrong. Try debugging a 768-dimensional embedding.
Here's what you give up. Embeddings capture a gradient - "executive compensation" clusters near "CEO pay" and "equity incentive plan." Expansion rules capture explicit relationships only. If a connection isn't in the map, it's missed.
In financial text, that gap is smaller than you'd expect. XBRL's ~18,000-element taxonomy is bounded enough that expansion rules cover most of the concept space. The FinMTEB benchmark confirms it: bag-of-words outperforms dense embeddings on financial similarity tasks. Hybrid search beats either alone – that's on the roadmap.
What you keep: zero infrastructure cost versus ~$5,000 setup and $300-500/month for a managed vector pipeline. Deterministic results. Inspectable logic. And a keyword layer that becomes half a hybrid stack, not something you throw away. The implementation is documented at the disclosure search feature page for anyone who wants the specifics.
What this looks like in practice
Back to that Amazon 10-Q here's what happens when all five techniques work together on edgar.tools.
If you know the name, search "Anthropic." Direct keyword match. Every mention across Amazon's filing history comes back with the filing period, disclosure label, and a highlighted snippet.
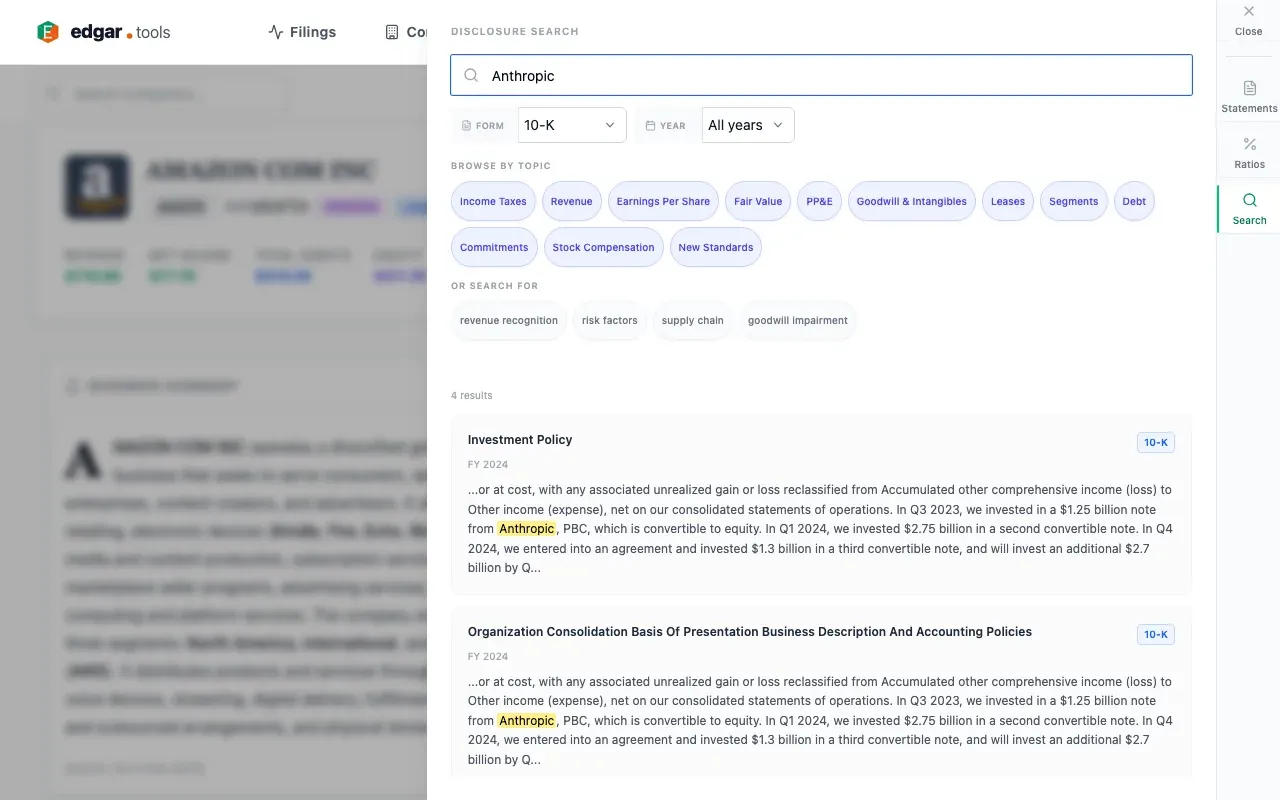
If you know the instrument type, search "convertible." The query expands to "convertible notes" and "convertible debt", catching the passages about Anthropic's convertible notes converted to nonvoting preferred stock – even if the user didn't think to search "notes".
If you're discovering without a keyword, browse the Fair Value topic. The system retrieves all Fair Value disclosures across Amazon's 10-K and 10-Q filings, organized as a timeline. The Anthropic preferred stock disclosures appear alongside related fair value measurements. No keyword required.
Each result links to the specific filing. Click to expand and the original disclosure text renders inline, exactly as filed with the SEC. The Amazon disclosures referenced above are browsable here: amazon.com/disclosures.
Boeing's legal disclosures show a different dimension: two overlapping threads resolving at different rates. The 737 MAX litigation accumulated through a 2021 deferred prosecution agreement, Boeing's failure to meet its terms, and a May 2025 non-prosecution agreement requiring a $244 million fine and $445 million in victim compensation. While that thread was closing, the January 2024 door plug accident opened a second one –customer concession liability tracked separately in the same disclosure section.
Changed-text filtering isolates the filings where each thread actually moved. Novelty scoring surfaces the inflection points: the year Boeing's warranty estimate changed by $737 million in a single filing, signaling ongoing uncertainty about product costs even as the legal threads resolved.
For analysts covering a peer group, the search runs across companies simultaneously – searching "revenue recognition" across a set of companies returns per-company results sorted by most recent filing, without reading ten 10-Ks cover to cover.
The implementation details are documented at the disclosure search feature page
The pattern beyond the product
None of this required embeddings. The compiler approach generalizes to any structured domain where vocabulary is bounded: use a frontier model to understand the domain, have it generate the search logic as code, ship the code, turn off the model. You trade the theoretical coverage of continuous embeddings for transparency and determinism. In domains where users need to trust their results, that's often the right trade.
If you're in that situation with SEC filings specifically, the search is live and free at edgar.tools/disclosures.
You don't need a RAG pipeline with embeddings to search SEC filing narratives. Neither did we.