The AI Ecosystem Around EdgarTools
See how the most popular Python library for SEC EDGAR data became the default financial data layer for AI projects: from model training to RAG to MCP servers.

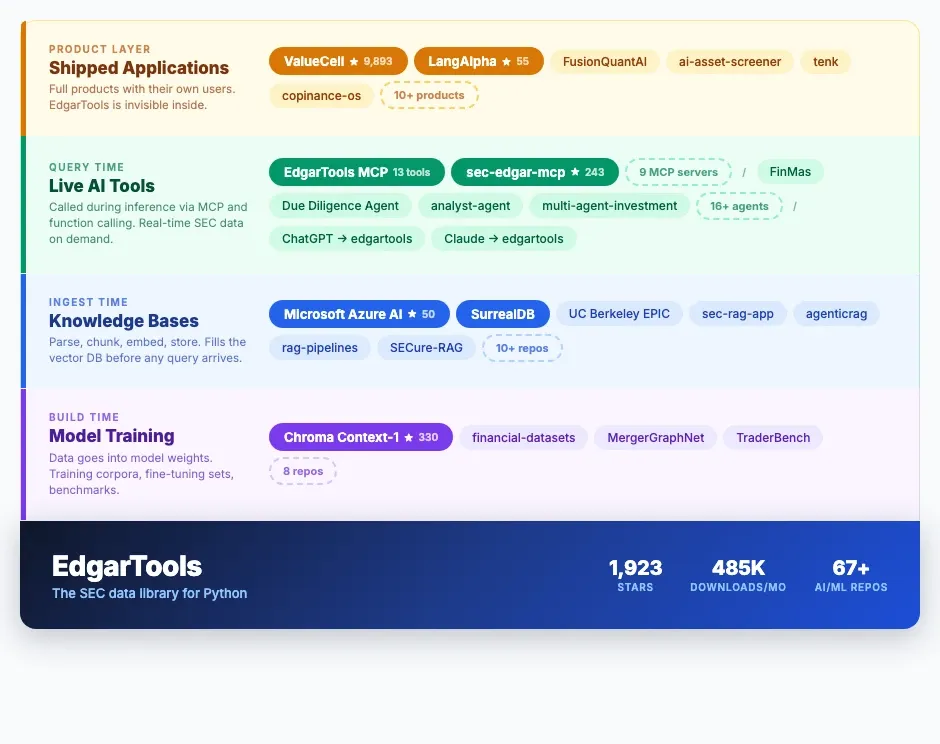
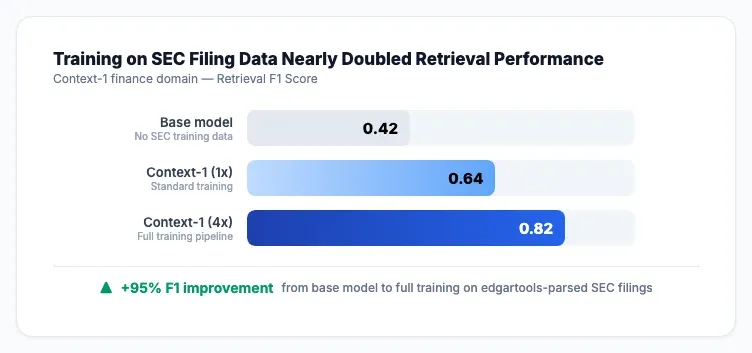
In March 2026, Chroma published Context-1 — a 20-billion-parameter search agent trained on four domains. For the finance domain, they parsed 7,264 SEC filings using edgartools. Finance hit 93% verification accuracy, the second-highest of any domain. Training on that data nearly doubled retrieval performance.
That would make a good story on its own, but Chroma is one of 67+ AI and ML projects that depend on edgartools. Microsoft's Azure-Samples org uses it in an agentic RAG workbench and SurrealDB uses it in their RAG and graph examples. At present there are at least eight separate MCP servers built around edgartools, not counting the official MCP server inside the library. ChatGPT and Claude both refer users to it when asked about SEC data.
The library was created in late 2022 and has grown alongside the post-ChatGPT AI boom. AI builders adopted it because nothing else parsed SEC filings reliably at scale. This article maps that ecosystem for the first time.
When Does EdgarTools Touch Your Data?
The easiest way to understand the ecosystem is by when edgartools runs relative to your AI system. Each layer solves a different problem.
SEC Filings as AI Training Data
At this layer, edgartools parses SEC filings into the training corpora, fine-tuning datasets, and evaluation benchmarks that shape model weights. This happens once, offline, and the model carries the knowledge forward.
Chroma Context-1 is the headline example. Their data pipeline:
- Sampled 1,707 random companies from SEC EDGAR
- Parsed 7,264 10-K and 20-F filings using edgartools
- Chunked the filings (average: 31,500 tokens per filing)
- Generated synthetic multi-hop questions requiring facts from multiple chunks
- Verified extraction accuracy at 93%
The result: Context-1's finance retrieval F1 score jumped from 0.42 (untrained baseline) to 0.82 after training — and 97% of queries found the correct final answer.
from edgar import Company
# This is the kind of pipeline Chroma built —
# edgartools handles the parsing, you handle the rest
company = Company("MSFT")
filing = company.get_filings(form="10-K").latest(1)
tenk = filing.obj()
# Structured sections ready for chunking
md_a = tenk["Item 7"] # Management Discussion & Analysis
risk = tenk["Item 1A"] # Risk FactorsFinance domain had the second-highest data quality of Context-1's four training domains:
| Domain | Source | Verification Accuracy |
|---|---|---|
| Legal | USPTO patents | 98.3% |
| Finance | SEC filings via edgartools | 93.0% |
| Epstein + Enron emails | 87.5% | |
| Web | Wikipedia + web scraping | 84.4% |
Why so high? SEC filings are legally mandated disclosures. Companies are liable for accuracy. Auditors verify the numbers. The data has been through more quality control than almost anything on the open web.
Other build-time projects:
- virattt/financial-datasets — curated financial datasets for ML training
- CagataySavasli/MergerGraphNet — graph neural networks for M&A prediction using SEC filing data
- yxc20089/TraderBench — financial benchmarks for LLMs
SEC Filings for RAG and Knowledge Bases
edgartools populates the vector store, search index, or knowledge graph that your system queries over. The filings are parsed, chunked, embedded, and stored before any user question arrives. This is the classic RAG architecture.
Microsoft chose edgartools for adaptive-rag-workbench, their official Azure AI Foundry reference architecture for context-aware agentic RAG with multi-source verification. When Microsoft needed to show developers how to build production RAG over financial documents, they reached for edgartools.
SurrealDB uses it in their official examples — SEC filings ingested into SurrealDB as vectors and knowledge graphs for financial Q&A. When a multi-model database company needs to demonstrate RAG and graph queries together, SEC filings are the dataset and edgartools is the parser.
UC Berkeley's EPIC Lab uses edgartools in docetl-examples to download 8-K filings and process them through their LLM-powered document transformation framework.
The RAG category alone includes 10+ repos: mindria-ai/sec-rag-app, akshata29/agenticrag, avnlp/rag-pipelines, xoxo121/SECure-RAG, Neel-K26/Advanced-RAG-Pipeline, Kurry/chromadb-company-sec-filings, and others. The pattern is always the same: edgartools parses the filing, an embedding model chunks it, a vector database stores it, and an LLM retrieves from it.
from edgar import Company
# A typical ingest pipeline starts here
company = Company("NVDA")
filings = company.get_filings(form="10-K").head(5)
for filing in filings:
tenk = filing.obj()
# Each section is already extracted and cleaned
for item in ["Item 1", "Item 1A", "Item 7", "Item 8"]:
text = tenk[item]
# → chunk, embed, store in your vector DB
MCP Servers and AI Agents for Live SEC Data
This is the fastest-growing layer. edgartools is called during inference — the LLM reaches out to SEC EDGAR on demand, in response to a user's question. No pre-indexing required. The standard that makes this work is MCP (Model Context Protocol).
The MCP Server Phenomenon
Eight independent teams built MCP servers around edgartools — without coordination, without being asked. When that many people solve the same problem the same way, you're looking at a genuine gap in the infrastructure.
EdgarTools ships its own MCP server — 13 intent-based tools, zero API keys, structured access to every SEC filing ever made. Unlike API wrappers that expose endpoints, the tools are organized around what analysts actually ask:
| Category | Tools | What They Do |
|---|---|---|
| Discover | edgar_company, edgar_search, edgar_screen, edgar_text_search, edgar_monitor |
Find companies, search filings, screen by industry, monitor live SEC feeds |
| Examine | edgar_filing, edgar_read, edgar_notes |
Parse any filing into structured data, extract specific sections, drill into disclosures |
| Analyze | edgar_trends, edgar_compare, edgar_ownership, edgar_fund, edgar_proxy |
Revenue time series, peer comparison, insider trades, fund holdings, executive comp |
Setup takes two minutes:
{
"mcpServers": {
"edgartools": {
"command": "uvx",
"args": ["--from", "edgartools[ai]", "edgartools-mcp"],
"env": {
"EDGAR_IDENTITY": "Your Name your.email@example.com"
}
}
}
}That's it. No API key, no signup, no usage dashboard. Ask Claude "What did Apple report last quarter?" and it pulls the real numbers from the actual filing.
The community MCP servers show the breadth of demand:
- stefanoamorelli/sec-edgar-mcp (243 stars, 64 forks) — the most popular third-party implementation. PyPI, Docker, and conda distribution. Academic DOI citation. Promptfoo evaluation suite.
- dynamicdeploy/edgartools-mcpserver — Docker-based wrapper
- sareegpt/edgartools-mcp, huweihua123/stock-mcp, cotrane/mcp-edgar-sec, druce/deep-research-machine, and others
The ai-integration.md page has the highest unique-view ratio of any page in the edgartools repository. The .claude/ directory is a top-10 viewed path — people are studying the Claude Code integration to build their own.
AI Agents
Beyond MCP servers, 16+ agent projects use edgartools as their SEC data backbone:
- KevorkSulahian/FinMas — agentic LLM for financial analysis
- Hariharan-afk/Automated-Due-Diligence-Agent — automated due diligence and market intelligence
- jacob187/analyst-agent, jabelk/advisor-agent — financial analyst and advisor agents
- flash131307/multi-agent-investment — multi-agent investment system
- sosodennis/value-investment-agent, dagudelo88/A.R.G.U.S, lucasastorian/intellifin-agent, and more
LLMs as a Discovery Channel
This one surprised me. ChatGPT and Claude both send users to edgartools when they ask about SEC data:
| Referrer | Views (14-day window) |
|---|---|
| chatgpt.com | 25–58 |
| claude.ai | 23–26 |
LLMs have become a discovery channel for the library itself. Users ask "How do I get SEC filings in Python?" and the model recommends edgartools by name.
Fintech Products Built on EdgarTools
edgartools is a dependency in full applications that end users interact with. At this layer, the library becomes invisible — users see the product, not the parser underneath.
- ValueCell-ai/valuecell (9,893 stars) — community-driven multi-agent platform for financial applications. The largest indirect distribution channel. Every ValueCell user is an edgartools consumer.
- ginlix-ai/LangAlpha (55 stars) — "From Vibe Coding to Vibe Investing"
- DDMYmia/FusionQuantAI — quantitative AI platform
- evgenyigumnov/ai-asset-screener — AI-powered asset screening
- ralliesai/tenk — AI analysis of 10-K filings
Why SEC Filings Make Better AI Training Data Than Web Scrapes
Chroma's Context-1 results quantify something practitioners have been discovering on their own: SEC filings make better AI training data than most web sources.
Here's why:
Regulated and verified. Companies are legally liable for what they file. The data has been reviewed by lawyers, auditors, and compliance teams before it reaches EDGAR. There is no equivalent quality control for web-scraped text.
Structured by design. XBRL tags, standardized section headers (Item 1, Item 1A, Item 7...), consistent HTML formatting across form types. SEC filings are machine-readable not by accident but by regulation.
Massive scale. 667,000+ reporting entities. Decades of filings. Multiple form types — 10-K, 10-Q, 8-K, 13F, Form 4, DEF 14A, and dozens more. Multi-modal: text narratives, financial tables, exhibits, all in the same document.
Free and public. No licensing barriers. SEC explicitly provides bulk access. No terms-of-service restrictions on training data usage.
Proven quality. Context-1's 93% verification accuracy on finance vs. 84.4% on web data isn't a fluke. It's what you'd expect when your source material has been through auditor review and legal signoff.
The Numbers
| Metric | Value |
|---|---|
| GitHub stars | 1,923 |
| Forks | 334 |
| PyPI downloads/month | ~485K (~348K organic) |
| Dependent repos (total) | 245+ |
| AI/ML dependent repos | 67+ (~40% of all dependents) |
| Independent MCP servers | 8 |
| Tier-1 org dependents | Microsoft, Chroma, SurrealDB |
| LLM referral sources | ChatGPT, Claude |
| Competitors with AI ecosystems | None |
That last row matters. sec-edgar-downloader has ~5K monthly downloads and no AI dependents. secedgar has similar numbers. The competitive field for "SEC data library that AI teams actually use" is empty.
The Community Is Shaping EdgarTools for AI
The ecosystem isn't just consuming edgartools — it's pushing the library toward AI-native capabilities. Recent community contributions:
- #732 —
to_markdown()methods for LLM-optimized output - #731 — keyword-based cover page detection (improves text extraction for AI pipelines)
- #735 — Claude Desktop MCP schema compatibility fixes
- #654 — MCP tool responses for 10-Q narrative sections
When your users start submitting PRs to make your library work better with LLMs, you know the center of gravity has shifted.
Get Involved
EdgarTools is MIT-licensed, free to use, and requires no API key. Whether you're training a model, building a RAG pipeline, or wiring up an MCP server, the starting point is the same:
- GitHub — source code, issues, and discussions
- Documentation — quickstart guides, API reference, and the MCP server setup
- PyPI —
pip install edgartools - edgar.tools — a hosted platform built on edgartools with a visual filing browser, REST API, and MCP server — no infrastructure required
If you're using edgartools in an AI project, we'd like to hear about it. Open a discussion or give the repo a star — it helps others find the library the same way 67+ AI teams already have.