Speedup jobs with Local Storage
How you can use Local Storage in edgartools to make your filing analysis jobs faster

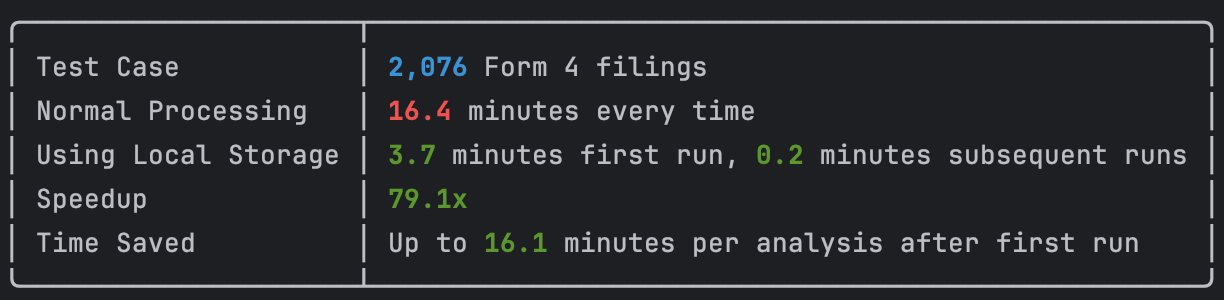
🚀 Real Results Highlight
The Problem: Repeated network calls
In the normal case when you call get_filings() or Company.get_filings() the library will fetch the filing indexes in as few network calls as possible.
The catch is that the filing indexes don't actually contain the filing documents or data, they only contain metadata about the filings. To access the actual filing data, you need to call filing.obj() which will download the filing document from the SEC.
This means that every time you call filing.obj(), it:
- Makes a network request to the SEC servers
- Downloads the filing document
- Parses the document to extract data
- Returns the parsed object
This process is slow and inefficient for large amounts of filings.
Example: Processing Form 4 Filings
As an example let's say you wanted to analyze Insider Transaction filings for a given day. For this you want to get Form4 filings and call filing.obj() on each to convert to a Form4 object with the data about the insider transaction.
The general pattern for processing Form 4 filings looks like this:
from edgar import *
from tqdm.auto import tqdm
# Fetch Form 4 filings for a specific date
filings = get_filings(form='4', filing_date='2025-01-14')
for filing in tqdm(filings):
form4 = filing.obj() # Downloads and parses the form4 XML document
data = form4.to_dataframe() # Converts to DataFrame
# Process transactions...The Form4 parsing code is fairly well optimized for what it does and you can get a throughput of between 2-3 Form4 objects per second.
Even so, due to the SEC rate limits there is a hard limit of 10 requests per second.
The Solution: Local Storage
Local storage solves this by:
1. Bulk downloading filings once to local disk
2. Caching parsed data for instant access
3. Eliminating network delays for subsequent runs
4. Enabling offline processing
Performance Comparison
We will compare the performance of processing Insider filings with and without local storage.
Without Local Storage (Baseline)
for filing in tqdm(filings):
form4 = filing.obj() # Makes network call
# Process transactions...With Local Storage (Optimized)
# One-time bulk download (upfront investment)
download_filings(filing_date='2025-01-14') # 30-60 seconds
# Lightning-fast processing from cache
for filing in tqdm(filings):
form4 = filing.obj() # Instant load from cache
# Process transactions...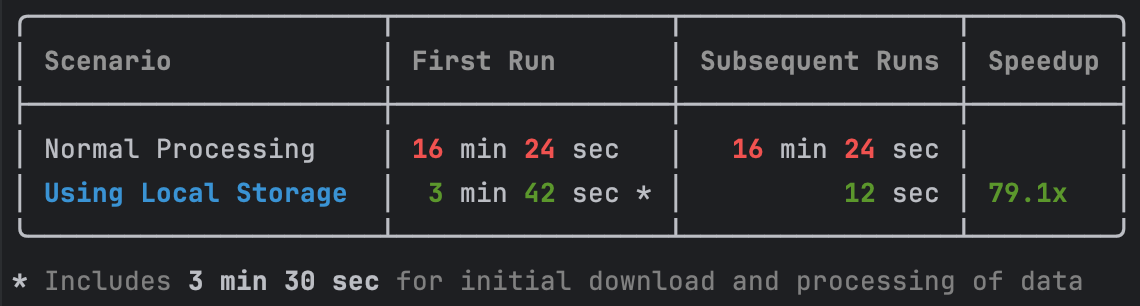
Key Insight: Local storage delivers immediate benefits (4.4x faster) on first run and exponential gains (79x faster) on subsequent runs.
Step-by-Step Implementation
Edgartools allows you to download filings to local storage before running batch jobs. When you set local storage on and download data ahead of time subsequent requests to get filings will be served from local storage.
1. Basic Setup
Local Storage is turned on by using the environment variable EDGAR_USE_LOCAL_DATA or by calling use_local_storage() .
You also need to specify the local directory to use by setting the environment variable EDGAR_LOCAL_DATA_DIR. By default this is set to USERHOME\.edgar
import os
from edgar import *
from tqdm.auto import tqdm
import time
filing_date = '2025-01-14'
# Enable local storage
use_local_storage()
os.environ['EDGAR_LOCAL_DATA_DIR'] = '/Volumes/T9/.edgar'2. Bulk Download Strategy
Now you can download filings for the dates you intend to process. This will download the SEC bulk filings file for that data and extract into EDGAR_LOCAL_DATA_DIR\filings\<filing_date>
def download_filings_bulk(filing_date: str):
"""Download all filings for a date in one operation"""
print(f"📥 Downloading filings for {filing_date}...")
start_time = time.time()
# This downloads ALL filings for the date
download_filings(filing_date=filing_date)
download_time = time.time() - start_time
print(f"✅ Bulk download completed in {download_time:.2f} seconds")
return download_time3. Optimized Processing
Once local storage is enabled and filings are downloaded the filing attachments will be located on disk and most operations within the library will then use local storage, eliminating network calls.
def process_insider_transactions_optimized(filings):
"""Process filings with local storage optimization"""
print(f"\n🚀 Processing {len(filings)} filings WITH local storage...")
start_time = time.time()
results = []
successful = 0
failed = 0
for filing in tqdm(filings, desc="Processing filings (cached)"):
try:
form4 = filing.obj()
results.append(form4.to_dataframe())
successful += 1
except Exception as e:
failed += 1
continue
results_df = pd.concat(results, ignore_index=True)
processing_time = time.time() - start_time
return {
'results': results_df,
'processing_time': processing_time,
'successful': successful,
'failed': failed
}I say most because there are some operations that will still trigger network calls to SEC Edgar. For example there are some filing types e.g. Form "NO ACT" where the filing documents are scanned PDF uploads are the main filing document is just a file pointing at the scanned PDF. So the library makes a call to retrieve the actual document.
4. Complete Workflow
Here is the full workflow
def main():
# Step 1: Get filings list
print("📋 Fetching Form 4 filings...")
filings = get_filings(form='4', filing_date=filing_date)
print(f"Found {len(filings)} filings")
# Step 2: Bulk download (one-time cost)
download_filings_bulk(filing_date)
# Step 3: Lightning-fast processing
transactions = process_insider_transactions_optimized(filings)
# Step 4: Analyze results
print(f"\n📊 Analysis Results:")
print(f" Total transactions: {len(transactions)}")
print(f" Unique companies: {len(set(t.company_name for t in transactions))}")
print(f" Total value: ${sum(t.transaction_value for t in transactions):,.2f}")Storage Optimization
Storing all filings for a given day requires around 2GB. You can actually specify which filings to store to disk by first filtering filings then calling filings.download(). For example this will work
filings = get_filings(form="4", filing_date="2025-04-09")
filings.download()This will save only the Form 4 filings to disk. Note that this will not make downloading faster - the library still uses the same bulk file containing all filings - but there will be filtering on save to disk.
Future Enhancements
I am working on using Cloud Storage which means the library will use your cloud provider as the location for SEC filings instead of SEC Edgar.
Conclusion
This article showed how to use LocalStorage to speed up processing of batch jobs that analyze SEC filings.
If you find this article useful and would like to install and use edgartools you can install using
pip install edgartoolsFor more details on Local Storage view the documentation. If you like edgartools consider contributing and or supporting or just leaving a star on Github.