Parsing SEC 13F Holdings 8x Faster
Get SEC 13F-HR hedge fund holdings data in Python with edgartools. See how holdings change over time with quarter-over-quarter comparison — now parsing 8x faster

Every quarter, institutional investment managers with over $100 million in assets file Form 13F-HR with the SEC, disclosing their equity holdings. These filings are one of the most popular data sources on SEC EDGAR. Hedge fund watchers track them and Quant researchers screen them. And edgartools, a Python library for SEC filing analysis, parses them from raw XML into clean pandas DataFrames.
Recently I made two major changes to how edgartools parses 13F-HR Institutional Holdings. The first change was a visual change inspired by this post by Singularity Research on X

The first half of the post was about Gavin Baker head of Atreides Management. Gavin is a top hedge fund manager - his fund achieves comfortably better returns than the average fund - and it is worth taking a look at his strategy. But it was visuals in the second half of the post that got me interested in doing something similar in edgartools.
So I spent an afternoon coding the changes in the ThirteenF class. I added a HoldingsView class that retrieves multiple previous filings and renders like below in the terminal with the trend sparkline I was interested in. You get it by calling holdings_view on the ThirteenF
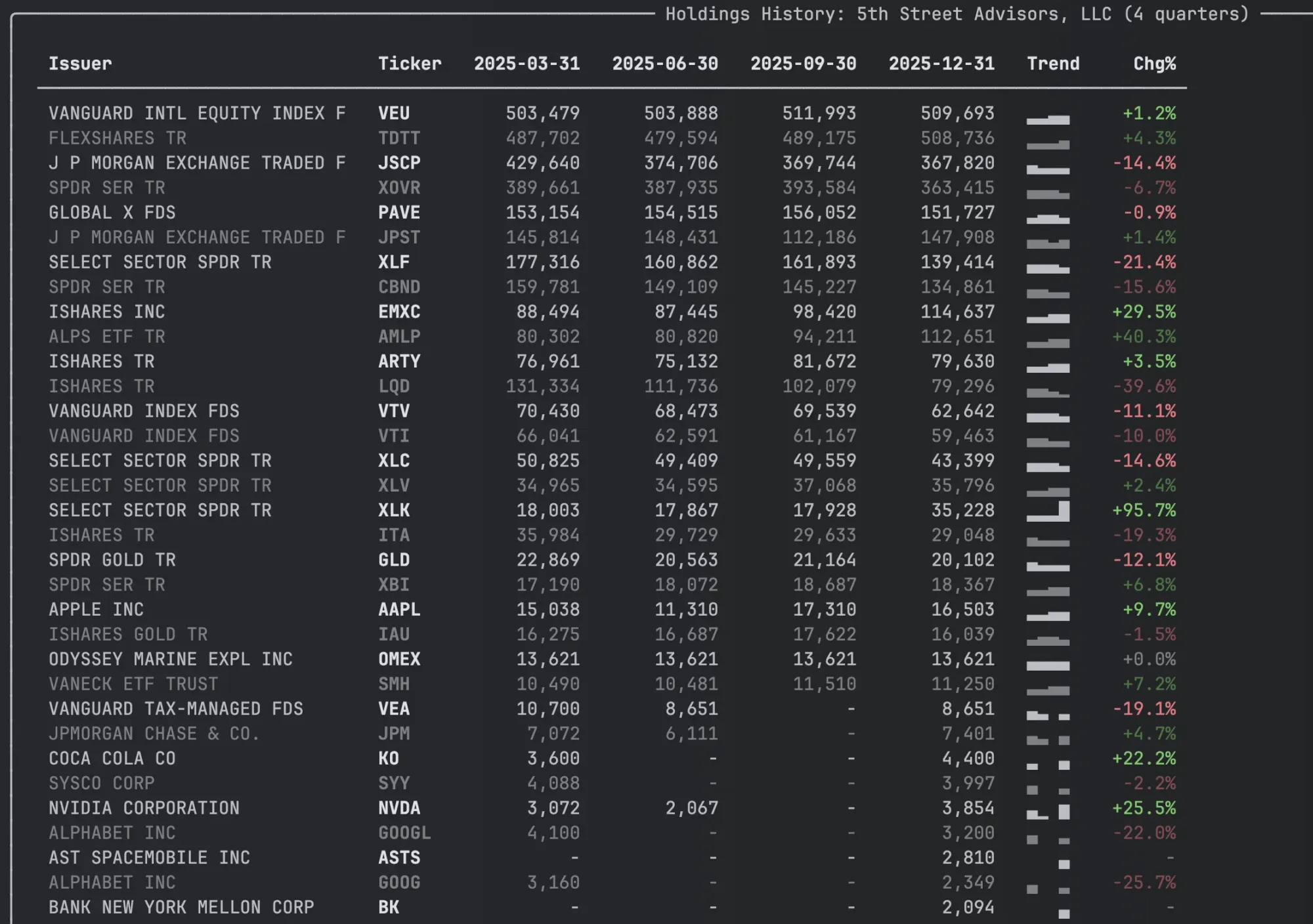
I also added a second view - HoldingComparison that has several columns showing changes over the previous quarter. You can get it by calling compare_holdings() on a ThirteenF object.
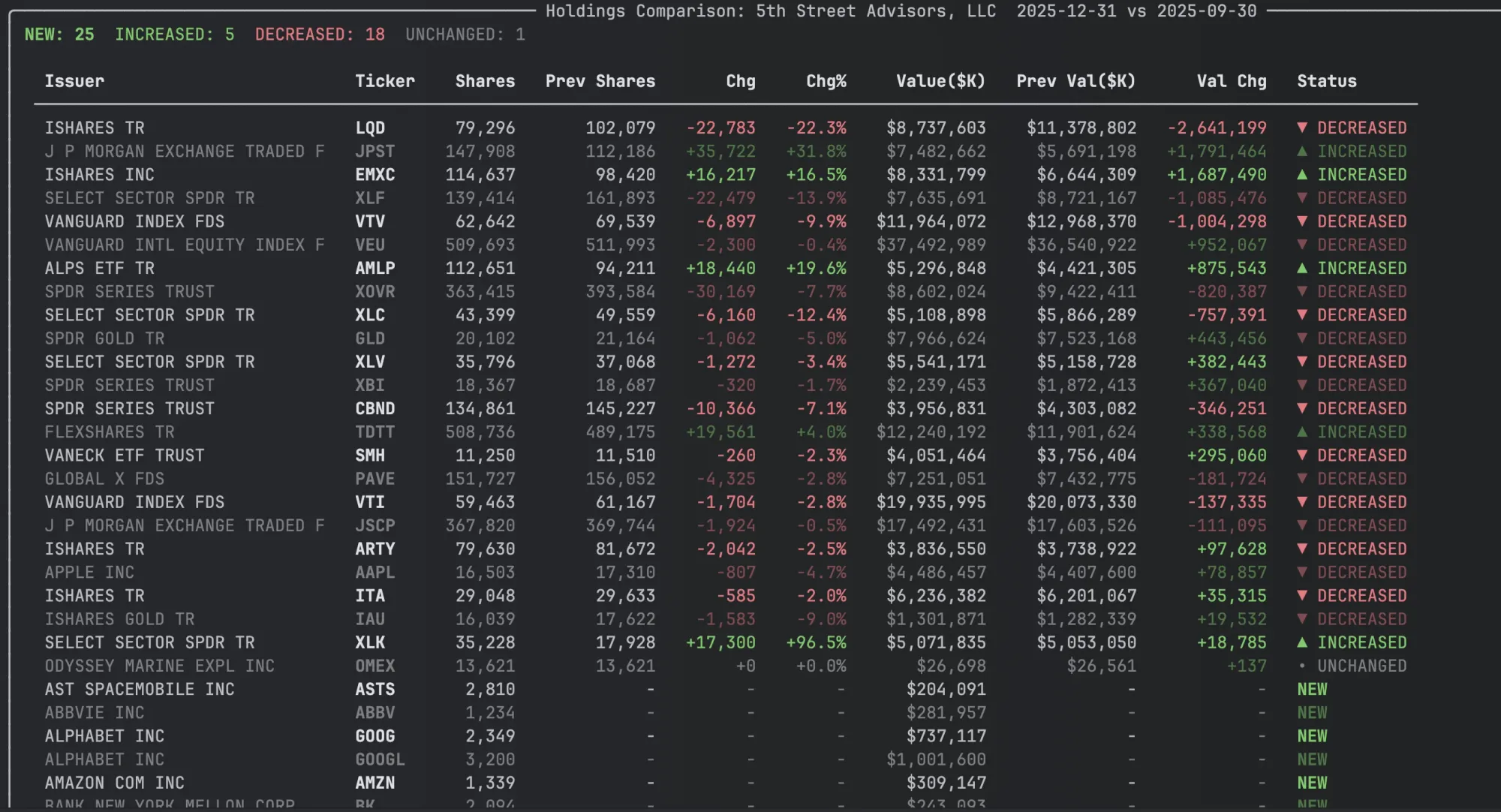
These visual additions to the Institutional Holdings components contributes to recent visual upgrades made to edgartools that are meant to improve the utility of the library but also make it more pleasant to work with. It's not just looks - you can iterate over the data in each view to integrate in your application.
The challenge with parsing large filings
What is life without beauty. What is beauty without performance. How wonderful would the experience be for a user waiting 24 seconds to view a 13F-HR?
Institutions like Vanguard and UBS can have really large portfolios with thousands of holdings. The data is contained in an infotable XML file that requires parsing. In the previous version of edgartools we used BeautifulSoup for parsing the XML and this is where the code spent 92% of the time.

How edgartools parses 13F-HR filings
When you call filing.obj() on a 13F-HR filing, edgartools runs a pipeline:
1. Download the SGML filing from SEC and parse it to find the attachments
2. Read the infotable XML attachment containing the actual holdings data
3. Parse the XML into structured data
4. Aggregate holdings by security (groupby CUSIP, sum shares and values, map tickers)
For small filings like MetLife with 6 holdings, this takes 5 milliseconds. For Berkshire Hathaway with 41 holdings, about 80ms. The issue was large multi-manager filings.
At the time I created the ThirteenF parser probably 2 years ago I optimized for a very scarce resource - my time. While most associate BeautifulSoup with HTML parsing it is also quite a capable XML parser with an approachable API. Using it meant I could write parsers for different filing types relatively quickly. I say relatively quickly but that was in early 2023 - almost the before times for AI coding. I'd say it would take me around 3-5 days to code a parser for a filing type depending on the complexity.
Nowadays with Claude Code that time has come down to 2-3 hours. With my confidence in Opus 4.5 supported by my extensive test suite I decided to do the rewrite.
Replacing BeautifulSoup with lxml
In v5.13.0, we rewrote the infotable parser to use lxml's etree API directly. The change was straightforward: etree.fromstring() to parse the XML, then element.find() and .text to walk the tree and extract each holding's 13 fields.

Profiling the optimized 13F parsing pipeline
With the parser swapped, we profiled again to see where time was being spent:

The SGML download and infotable download are network I/O, which we can't control from the library. The lxml engine parses 13 MB of XML into a tree in 70ms. The largest remaining chunk is the Python loop that walks the tree, calling element.find() and .text for 13 fields across 24,019 rows. That's inherent Python overhead for this volume of data. No more easy wins in the parser.
The pandas postprocessing, DataFrame creation, groupby, ticker mapping, sort, all of it together is about 42ms. Which brings us to the next question.
Optimizing pandas operations for 13F data
With the parser no longer the bottleneck, we turned to the pandas operations in v5.13.1. The new features we were building, compare_holdings() and holding_history(), involve multiple DataFrames across quarters and had some known slow patterns.
We made six changes in about 54 lines of code:
- Replaced iterrows() with itertuples() for iteration (13x faster per call)
- Replaced df.apply(_status, axis=1) with vectorized np.select() (50x faster)
- Eliminated an unnecessary 15 MB .copy() of the infotable DataFrame
- Added categorical dtypes for low-cardinality columns like Type and PutCall
- Batched numeric conversion into a single pass
- Switched to inplace operations in rendering
The individual numbers sound dramatic. 13x here, 50x there. But these operations were already a small fraction of total time. The overall improvement across the pandas-heavy operations was 11.7%. Useful, but not transformative - the major changes had already happened in the parser.
Why stick with pandas over polars?
I evaluated switching from pandas to polars. At 24,000 rows, the answer was clear: not worth it. Polars is faster for large-scale data processing. But the groupby on 9,000 aggregated rows takes 12ms in pandas. Even if polars cut that in half, we'd save 6ms out of a 1,200ms pipeline. The XML parsing and network I/O dominate. Polars wouldn't touch either of those.
Conclusion
The results were substantial performance gains for small files but much more importantly we could scale for really large data sizes. This means that you can feasibly include edgartools' 13F-HR parsing in your own data pipeline or application.

If you find this article useful try edgartools - the most powerful Python library for accessing SEC filing data. Head over to the Github project and read more about 13F-HR forms in the documentation.